Multi-DC Deployment Patterns - Overview¶
What is Multi-DC Deployment Architecture?¶
A multi-datacenter (multi-DC) deployment architecture in API management refers to a setup where an organization deploys its API management infrastructure across multiple data centers or geographic locations. This architecture is designed to improve the availability, scalability, and resilience of the API management system, ensuring that APIs are consistently accessible and performant for users across different regions.
Why Multi-DC Deployment?¶
A multi-datacenter (multi-DC) architecture is used for various reasons, primarily to address specific challenges and requirements that organizations face in the modern IT landscape. Here are some of the key reasons why multi-DC architectures are employed:
-
High Availability: Multi-DC architectures are designed to ensure high availability of services and applications. By distributing resources across multiple data centers, organizations can reduce the risk of downtime due to data center failures, hardware issues, or network outages. If one data center experiences problems, traffic can be redirected to another one.
-
Geographical Redundancy: For global businesses or organizations with a geographically dispersed user base, multi-DC architectures offer low-latency access to resources. Users can connect to the nearest data center, improving the overall user experience.
-
Reduced Latency: For latency-sensitive applications, having data centers closer to end-users can significantly reduce the time it takes for data to travel, resulting in faster response times.
-
Disaster Recovery: Multi-DC setups provide built-in disaster recovery capabilities. In the event of a catastrophic failure or natural disaster affecting one data center, organizations can switch operations to another data center, minimizing service disruption.
-
Scalability: Multi-DC architectures allow for horizontal scalability. Additional resources can be added to accommodate increased workloads and traffic. This is crucial for applications and services that experience fluctuating usage patterns.
-
Regulatory Compliance: Some industries and regions have specific data residency or compliance requirements. Multi-DC architectures can be used to store and process data in compliance with local regulations.
-
Data Backup and Replication: Multi-DC architectures often involve data backup and replication strategies to ensure data integrity and reduce the risk of data loss.
In summary, multi-datacenter architectures are adopted to improve reliability, scalability, and disaster recovery capabilities while meeting various operational and compliance requirements. They are especially important for organizations that need to ensure uninterrupted service delivery and data availability in today's interconnected and data-dependent world.
How WSO2 API Manager Supports Multi-DC deployment?¶
In WSO2, multi-data center deployments support two primary patterns, each catering to specific use cases and requirements. Choosing the right pattern is essential to meet the needs of your deployment. When scaling a deployment to a new region, a suitable pattern can be selected based on the requirements.
Take into account the following set of criteria for your new regional deployment
- The need for autonomous operation with access to the full suite of APIM features.
- A requirement to write data independently to the database in each regional context.
- The feasibility of database replication.
- Cost considerations that do not pose a constraint.
- The imperative for low-latency operations within the region.
- Disaster recovery where regions need to survive independently with all the features
In cases where the aforementioned criteria apply, Pattern 1 emerges as the optimal solution.
Alternatively, consider the following criteria for your upcoming regional deployment
Sole reliance on data plane components in the new regional context. The necessity for gateways to maintain proximity to backend systems. The infeasibility of database replication. Budget constraints that mandate a cost-effective approach.
When these criteria are relevant to your situation, Pattern 2 emerges as the ideal choice.
By carefully evaluating your deployment requirements and considering the scenarios and advantages of each pattern, you can make an informed decision on which pattern is the best fit for your multi-data center deployment with WSO2 API Manager.
Let’s take a look at the deployment architecture of the two patterns.
Note
WSO2 API Manager includes a resident key manager that serves as a robust solution for authentication and authorization purposes. During your deployment planning, it's essential to recognize the resident key manager as an integral component of the control plane. However, should your project necessitate the configuration of an external third-party Identity Provider (IDP), WSO2 API Manager's multi-data center deployment is designed to seamlessly accommodate this requirement. In this scenario, the API Manager treats the external IDP as a service, establishing communication through service calls. As long as the external IDP is made available to the relevant data centers, WSO2 API Manager can effectively integrate and function in conjunction with it.
This document provides in-depth guidance on setting up multi-data center deployments, by considering the resident key manager of WSO2 API Manager as the key manager which is included as a part of the control plane.
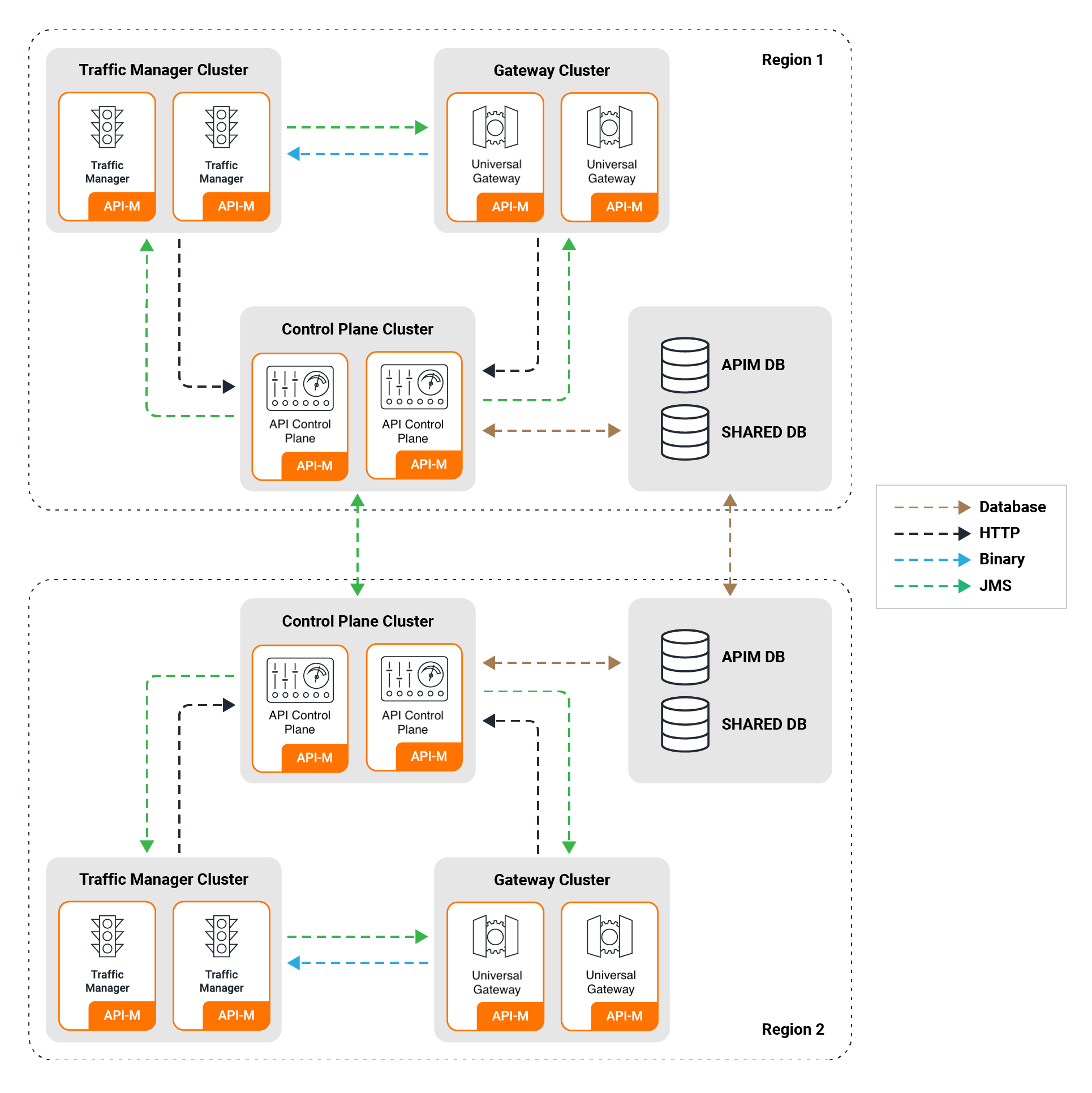
Pattern 1: Geo-Regional Synchronized API Management with Replicated Databases¶
Overview¶
Pattern 1 in a multi-datacenter (multi-DC) deployment of WSO2 API Manager involves the creation of multiple distributed setups connected by replicated databases and control planes (event hubs) across different regions. This configuration is designed to maximize high availability and ensure fault tolerance.
Note
WSO2 API Manager has been tested for DB replication only with MSSQL, Oracle and PostgreSQL DBs.
Advantages¶
- Since the control planes are available in each region, tasks such as API deployment, policy enforcement, application management, and policy creation/deletion can be done in each region.
- Ensures low latency for all operations since all tasks and features can be managed within the region. This is particularly important for applications with stringent latency requirements.
- Regions can survive independently with all the features, providing a robust disaster recovery solution.
Things You Should Consider¶
- While pattern 1 allows each region to function independently and read-write of databases can happen in each region, you will need to allocate more resources than pattern 2 since all the components should be deployed in all the regions.
Key Components¶
- Distributed Setups: Multiple distributed setups of WSO2 API Manager are established in different data centers or geographical locations. Each setup includes Classic Gateway instances, Publisher/Store components, Key Manager instances and any other relevant components.
Note
Please note that both regions can be configured as all-in-one setups as well. It is considered as a fully distributed setup in order to aid the understanding of the communication among the components.
-
Database Replication: Database replication is implemented to ensure that the underlying databases of WSO2 API Manager are synchronized across all data center setups. This replication provides data redundancy and fault tolerance, allowing for consistent API configurations and subscription data.
-
Control Planes (Event Hubs): The control planes (Event Hubs) in each data center setup are interconnected to facilitate real-time communication and data synchronization. Control planes play a crucial role in managing and coordinating activities across distributed setups.
Please refer to the documentation for detailed information on configuring pattern 1.
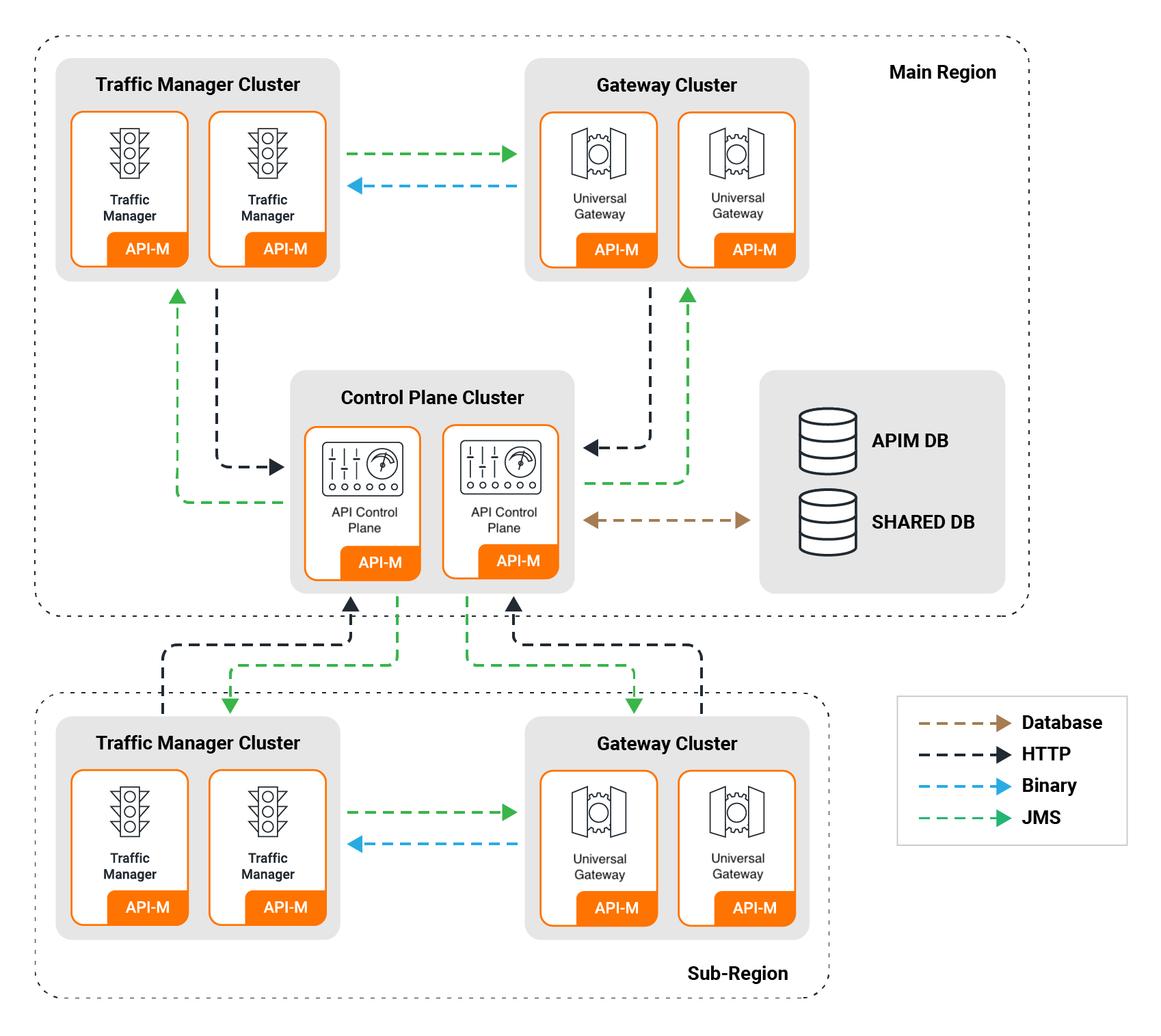
Pattern 2: Centralized API Management with Regional Data Planes¶
Overview¶
In Pattern 2 of a multi-datacenter (multi-DC) deployment of WSO2 API Manager, the architecture is designed with a clear division of roles. Specifically, one region acts as the central control point for the entire multi-DC deployment and is referred to as the "main region." Other regions, which are dedicated to handling incoming traffic and scaling needs, are known as the "sub regions."
Advantages¶
- Additional regions are equipped with gateways and traffic managers, reducing resource consumption as not all components/nodes need to be duplicated.
- If the backends are distributed across several regions, it is possible to add gateways closer to the backends with this architecture.
Things You Should Consider¶
- Since the control plane resides in the main region in pattern 2, in case of loss of connection or main region failure, communication between the control plane and gateway/traffic manager nodes will be disrupted. However, sub regions will still be capable of handling incoming traffic and perform throttling within the regions with the existing data. Once the main region control plane is connected again, the data will be synced to the sub region.
- The gateways in the sub region depend on the main region control plane for API related data when starting the server. Therefore, gateway nodes in the sub region can only be restarted/started after the control plane is connected.
Key Components¶
-
Main Region: The main region houses the control plane nodes and serves as the primary decision-making hub for the entire multi-DC setup. This region is responsible for administrative tasks, such as API publishing, management, and policy enforcement.
-
Sub Regions: Sub regions are configured to handle incoming traffic exclusively. These regions consist of gateway nodes and traffic manager nodes and are scaled independently to cater to traffic load. The sub regions play a vital role in distributing and managing the actual API traffic.
-
Horizontal Scalability: This documentation provides information on configuring a single main region with a single sub region. However, the deployment can be horizontally scaled as needed by adding multiple sub regions. This approach ensures flexibility and responsiveness to changes in traffic patterns and loads. Please note the recommendations mentioned here when scaling the Gateways.
Please refer to the documentation for detailed information on configuring pattern 2.
Note
Both pattern 1 and pattern 2 supports throttling based on the region/geographical area by default. Therefore, throttling will be handled independently for each region from their respective data center traffic.
FAQ¶
What pattern should I use if I have 2 regions where both require the capability to access features such as creating/publishing APIs, creating applications, and performing admin tasks with low latency?
For the above requirement, Pattern 1 is the most suitable choice. In Pattern 1, control plane nodes are distributed across all the regions, enabling access to the mentioned features from all regions locally with minimal latency. This configuration ensures that users in each region can efficiently perform tasks like API creation, publishing, application management, and policy administration, meeting low-latency requirements.
I have an API deployment in a single region, and upon inspecting APIM traffic, it was observed that API traffic from another region has suddenly increased significantly. What should be the strategy for addressing this situation?
In this scenario, you can opt for either Pattern 1 or Pattern 2, depending on your specific requirements. Pattern 1 is the choice when you need all the control plane functionalities from the newly added region. However, Pattern 2 is suitable if the region with increased API traffic primarily requires efficient traffic handling, without the need for additional API management features.
I currently have an APIM deployment in one region, with all components residing there. However, the deployed API backends are in another region, and customers from that region utilize these APIs. How can this inefficiency be addressed?
When dealing with a substantial number of customers from the region where the backends are hosted, the existing traffic handling can be inefficient.
To overcome this inefficiency, consider utilizing Pattern 2. By adding a sub region within the same region as the backends, you can optimize the gateway-to-backend communication. In this setup, the gateway and backend communication does not need to occur across different regions, resulting in improved efficiency. This pattern helps enhance the performance and responsiveness of your API deployment in multi-region scenarios.