Load Balancing¶
Load balancing ensures that AI API requests are efficiently distributed across multiple models within the same AI Service Provider, preventing overloading of any single model. WSO2 API Manager supports the following load balancing methods:
- Round Robin
- Weighted Round Robin
Note
You can only configure a single load balancing stratgery at a given time for a given AI API.
Round Robin¶
With Round Robin policy, requests are evenly distributed across all configured AI models in a cyclic manner, ensuring equal request allocation over time.
Configure Round Robin Routing¶
You can enforce round robin based load balancing for your AI API by attaching the Model Round Robin policy. Here are the steps that you need to follow:
- Login to the Publisher Portal (
https://<hostname>:9443/publisher). - Select the AI API for which you want to configure load balancing.
- Navigate to API Configurations, and click Policies.
-
Look for the policy named Model Round Robin listed under the Common Policies section within the policy list. Let's, drag and drop the Model Round Robin policy to the Request flow of
/chat/completionsPOST operation.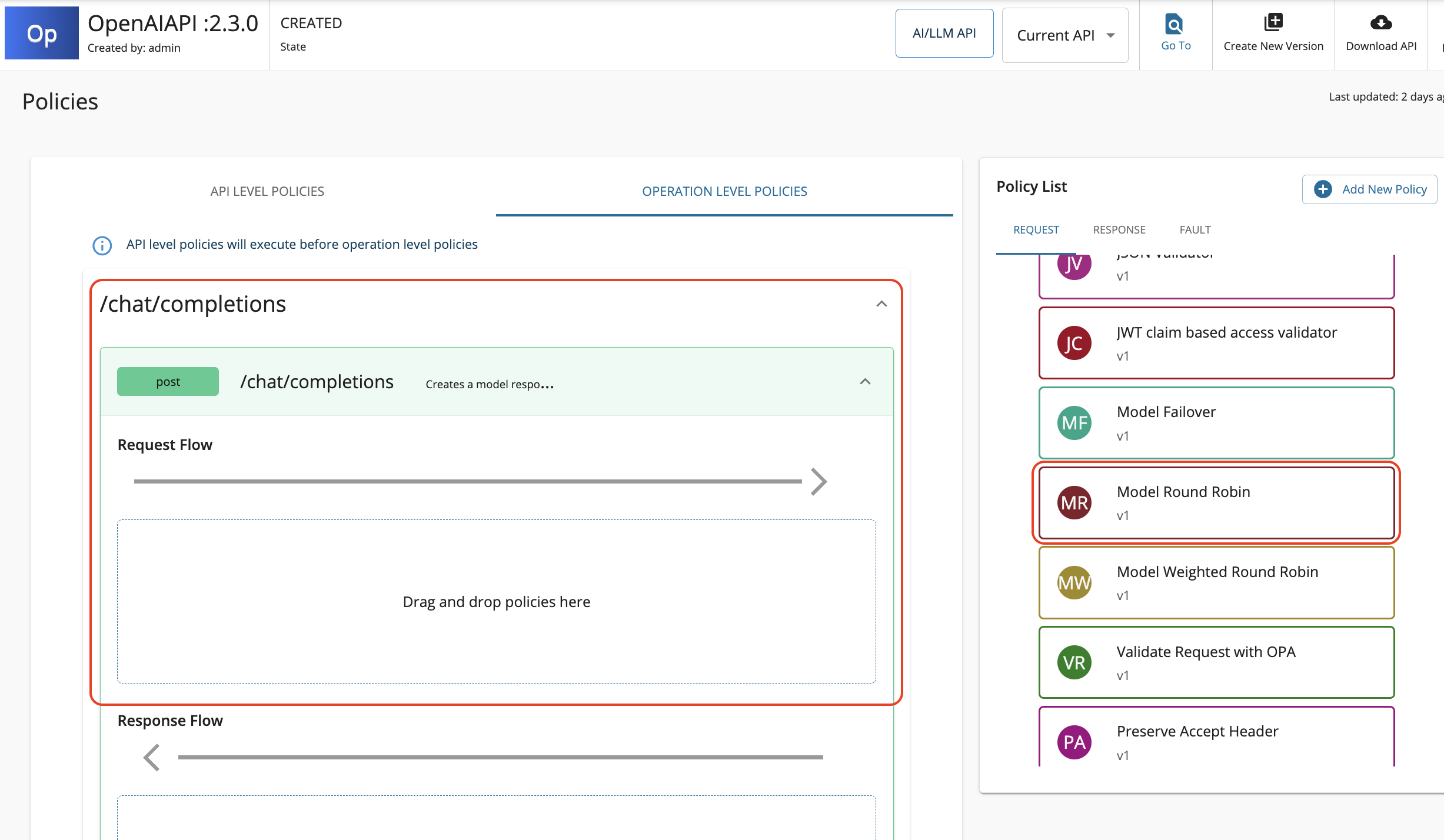
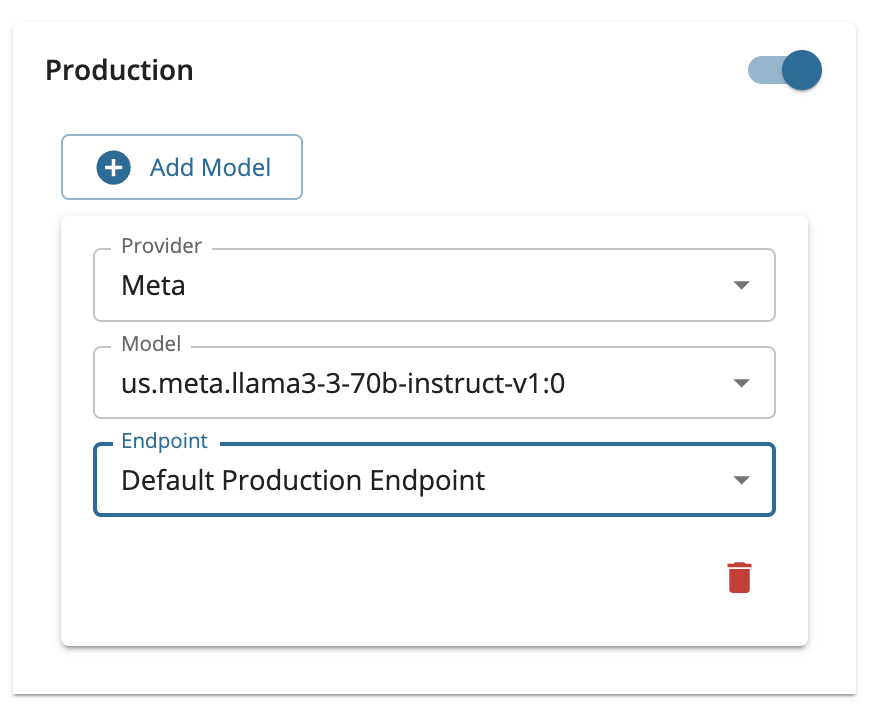
AWS Bedrock Configuration
When configuring a multi model provider service for round robin routing, you must select both the Provider (model family) and the Model for each model entry. The Provider dropdown will show the model families you have configured in the Admin Portal (such as Meta, Anthropic, DeepSeek, etc.). After selecting a provider, the Model dropdown will list the specific models available under that provider.
-
Fill in the requested details and click Save.
Section Description Production/Sandbox Add any amount of models by clicking on Add Model button. For each model addition, select a model from the dropdown (if no models are listed, make sure to add the desired models from the Admin Portal). Following the model selection, select the endpoint from the dropdown (if no endpoints are listed, make sure to add the required endpoints under the Endpoints page of Publisher Portal) Suspend Duration Suspend duration in seconds. This will be used to suspend any failed model-endpoint pairs. If not configured, knowledge about failed invocations are not persisted. 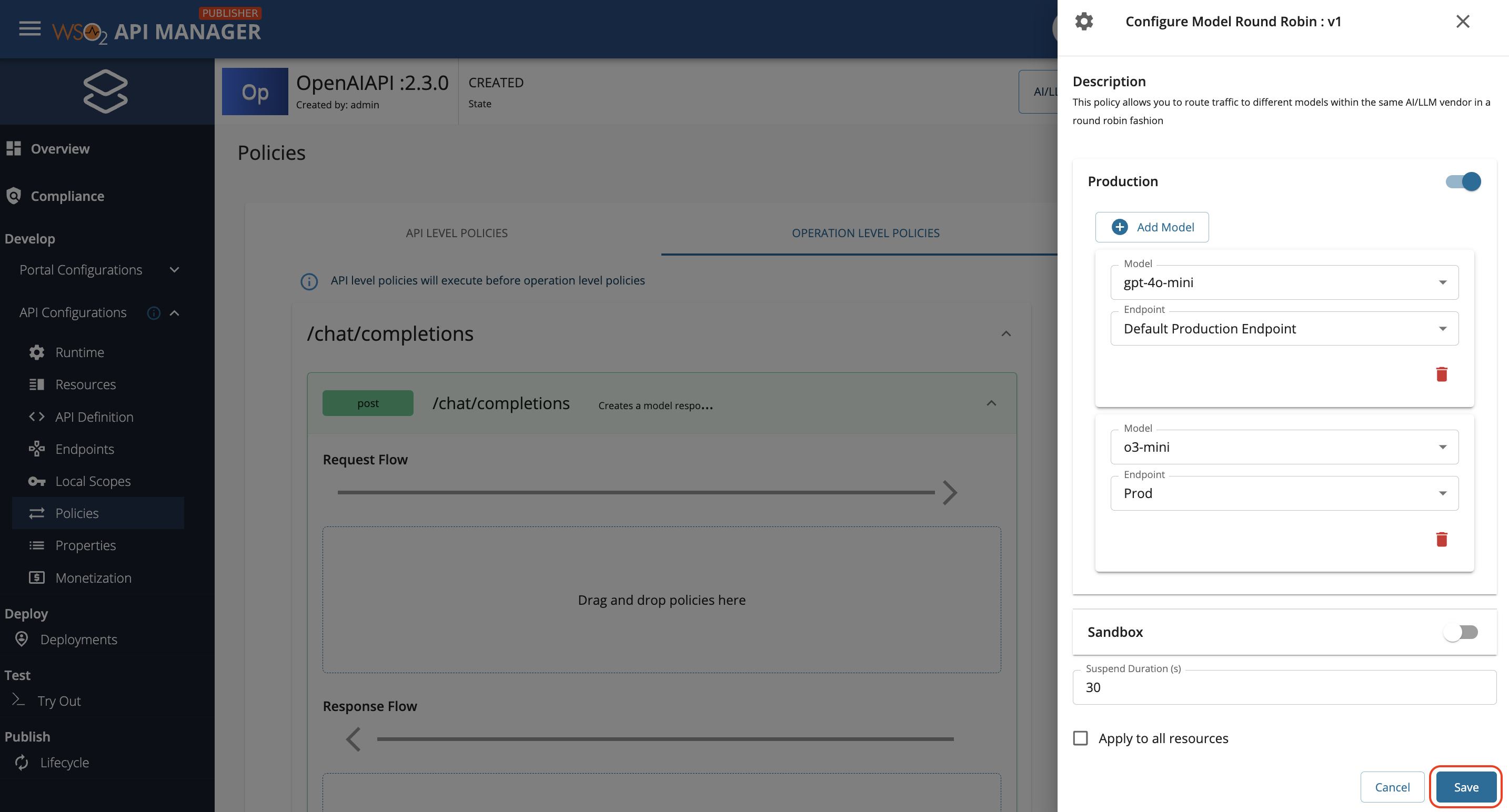
-
Finally, scroll to the bottom of the page and click on Save and deploy.
-
For more information on how to work with API Policies, refer to the API Policies section.
Try Out Round Robin Routing¶
- Navigate to the Developer Portal and try to invoke the AI API.
-
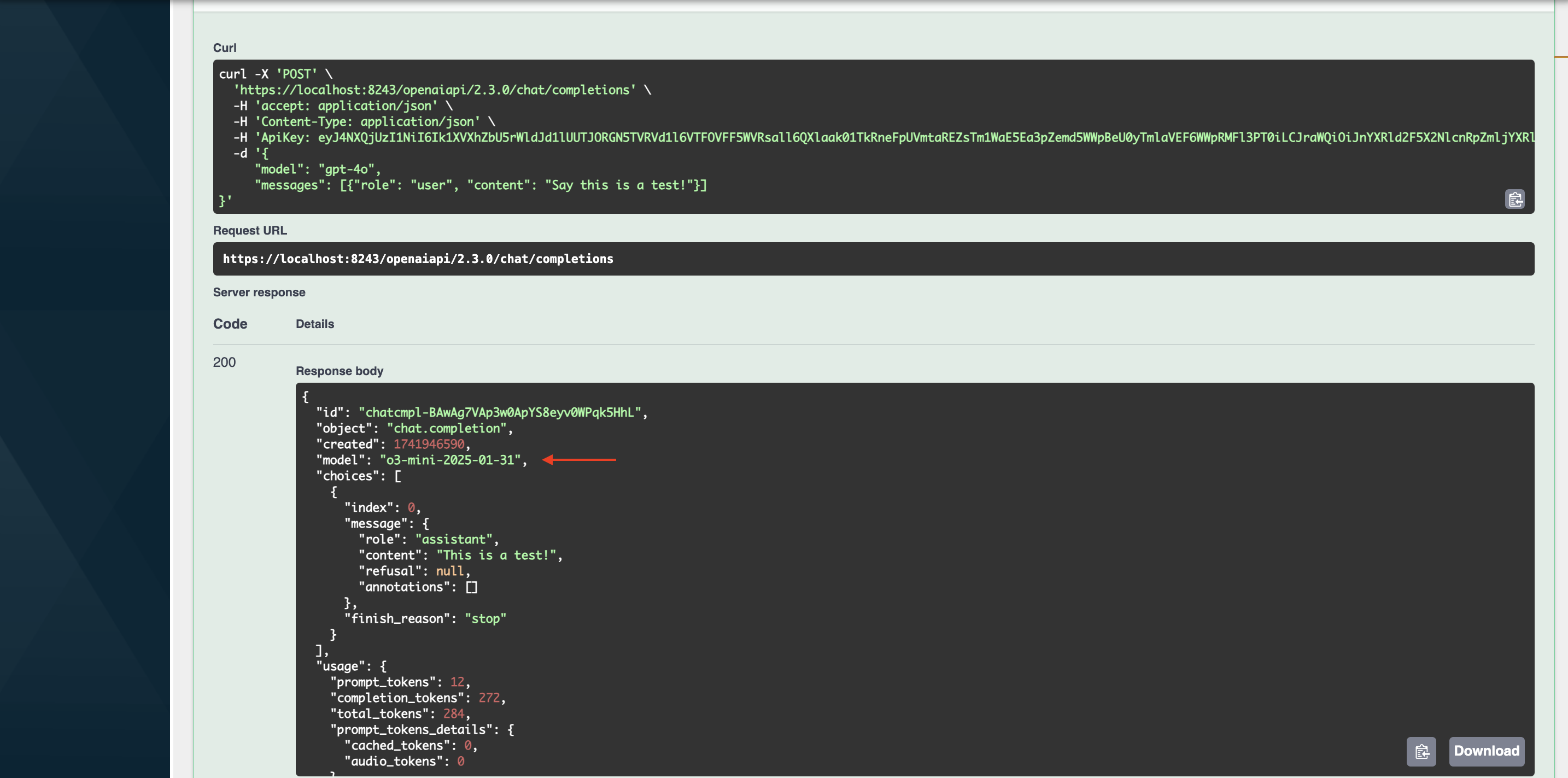
Let's invoke
/chat/completions POSTresource by obtaining a Production key since we configured the round robin policy only for production. You can use the below mentioned payload.{ "model": "gpt-4o", "messages": [{"role": "user", "content": "Say this is a test!"}] }Notice how the request was made to
gpt-4omodel, but the response was fromgpt-4o-mini.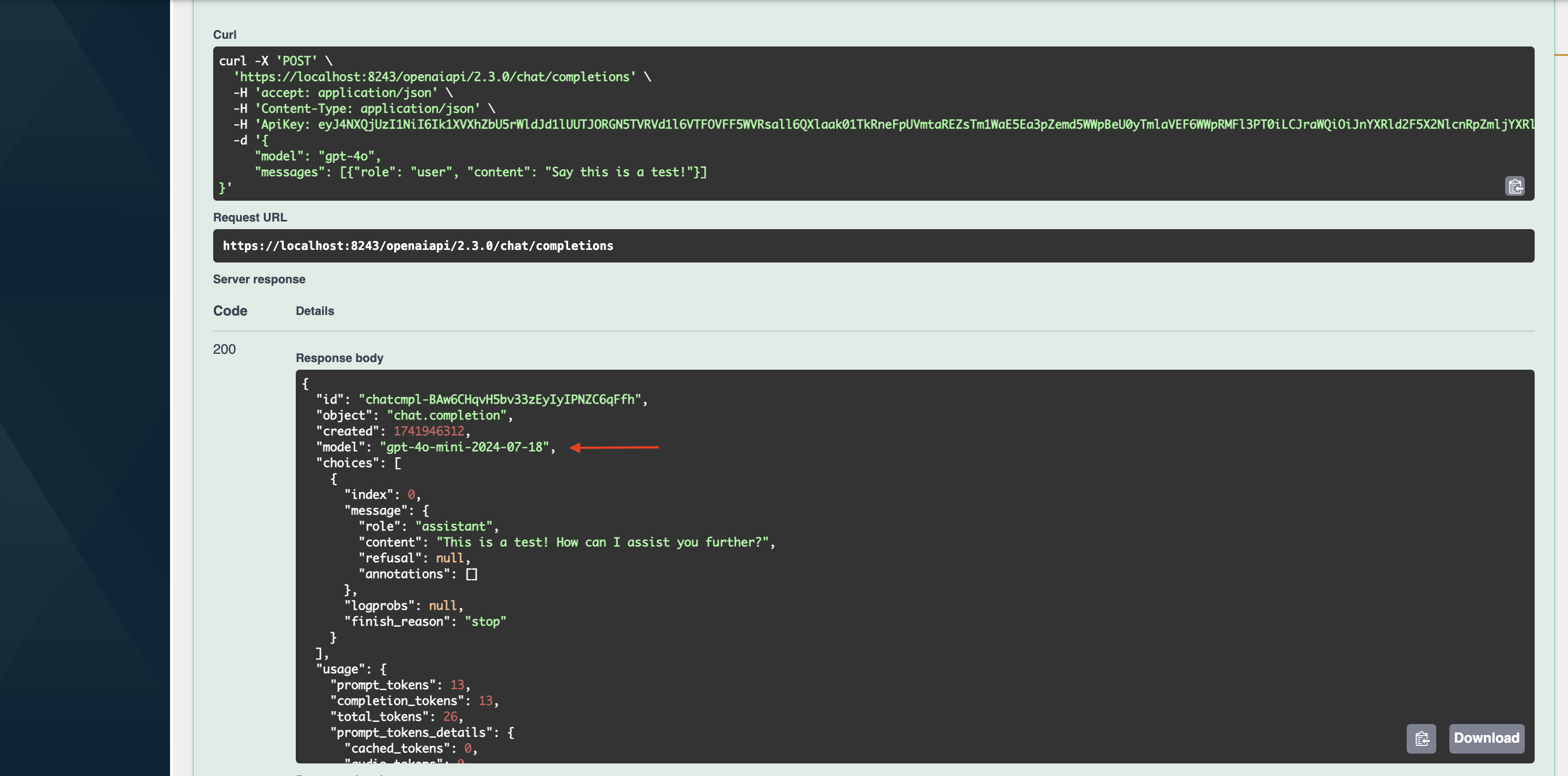
Weighted Round Robin¶
Requests are distributed based on predefined weight values assigned to each model. This allows probabilistic control over request distribution, giving higher priority to models with greater processing power or availability.
Configure Weighted Round Robin Routing¶
You can enforce weighted round robin based load balancing for your AI API by attaching the Model Weighted Round Robin policy. Here are the steps that you need to follow:
- Login to the Publisher Portal (
https://<hostname>:9443/publisher). - Select the AI API for which you want to configure load balancing.
- Navigate to API Configurations, and click Policies.
-
Look for the policy named Model Weighted Round Robin listed under the Common Policies section within the policy list. Let's, drag and drop the Model Weighted Round Robin policy to the Request flow of
/chat/completionsPOST operation.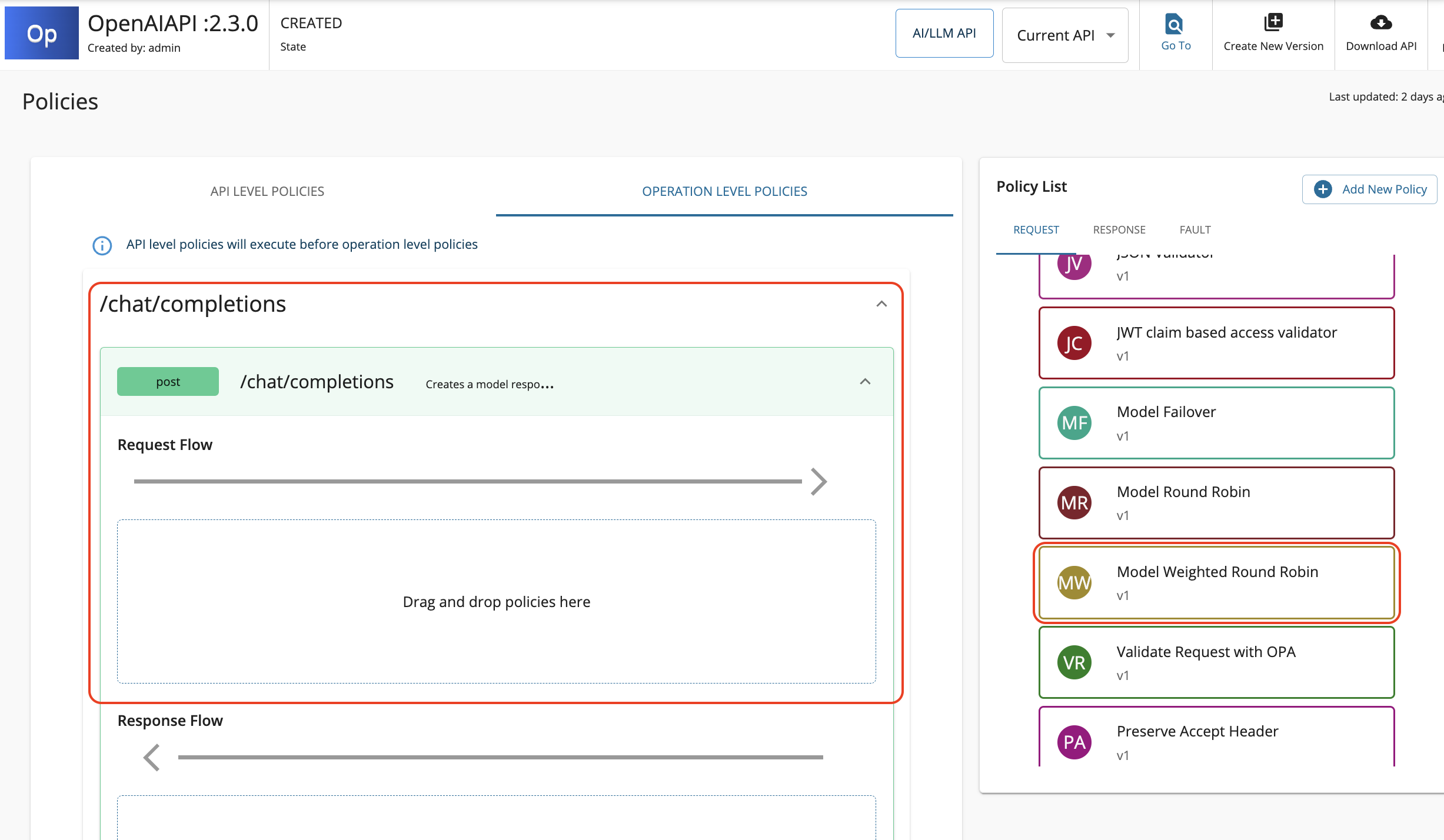
-
Fill in the requested details and click Save.
Section Description Production/Sandbox Add any amount of models by clicking on Add Model button. For each model addition, select a model from the dropdown (if no models are listed, make sure to add the desired models from the Admin Portal). Following the model selection, select the endpoint from the dropdown (if no endpoints are listed, make sure to add the required endpoints under the Endpoints page of Publisher Portal). Assign a weight to the model that was picked. Suspend Duration Suspend duration in seconds. This will be used to suspend any failed model-endpoint pairs. If not configured, knowledge about failed invocations are not persisted. 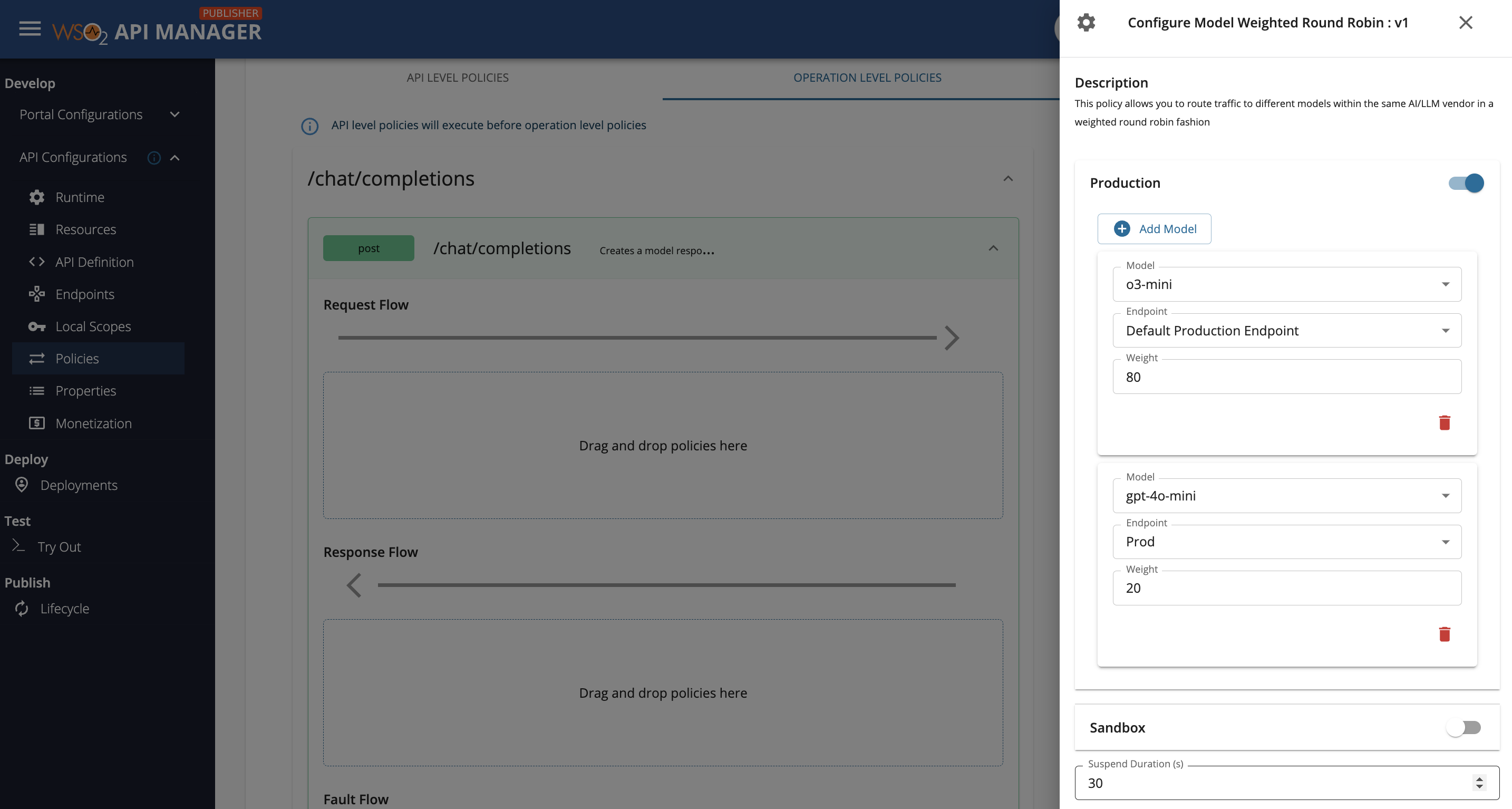
AWS Bedrock Configuration
When configuring a multi model provider service for weighted round robin routing, you must select both the Provider (model family) and the Model for each model entry. The Provider dropdown will show the model families you have configured in the Admin Portal (such as Meta, Anthropic, DeepSeek, etc.). After selecting a provider, the Model dropdown will list the specific models available under that provider.
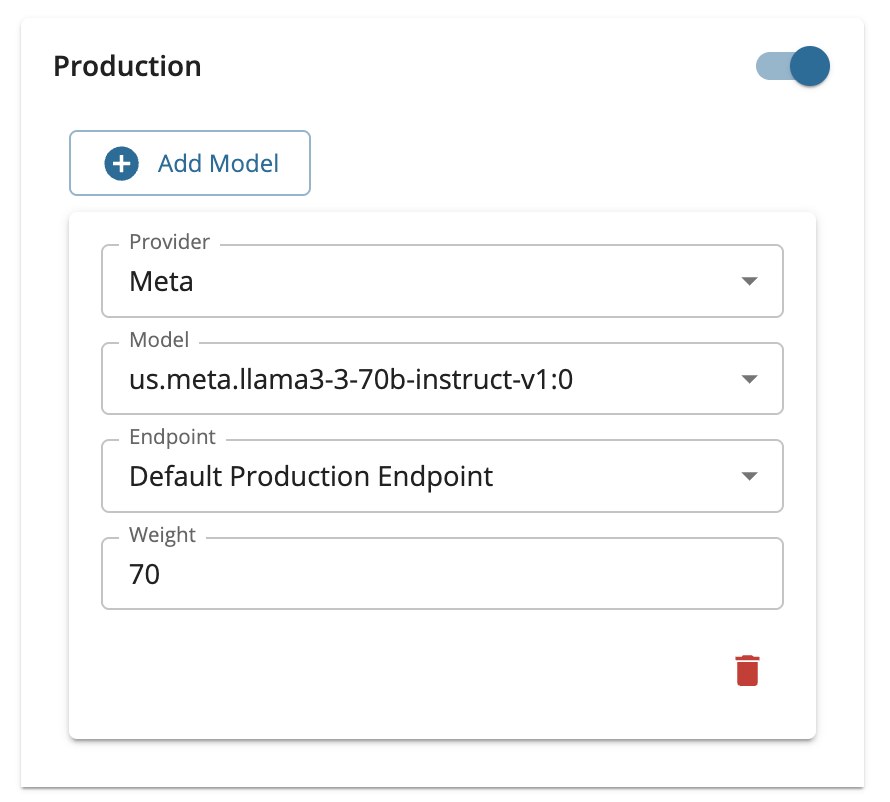
-
Finally, scroll to the bottom of the page and click on Save and deploy.
-
For more information on how to work with API Policies, refer to the API Policies section.
Try Out Weighted Round Robin Routing¶
- Navigate to the Developer Portal and try to invoke the AI API.
-
Let's invoke
/chat/completions POSTresource by obtaining a Production key since we configured the weighted round robin policy only for production. You can use the below mentioned payload.{ "model": "gpt-4o", "messages": [{"role": "user", "content": "Say this is a test!"}] }Notice how the request was made to
gpt-4omodel, but the response was fromo3-mini.